

A lot of work I've done over the past year for my research team revolved around face detection (using computers, of course. You and I can do it very easily). In this post, I'll describe the general principles behind how computers do it, and how it compares to what our brains do.
Imagine you give a computer an image or video, and then task it with doing "face detection". What is the goal of a computer when given this task?
Locate the faces
Label them as faces
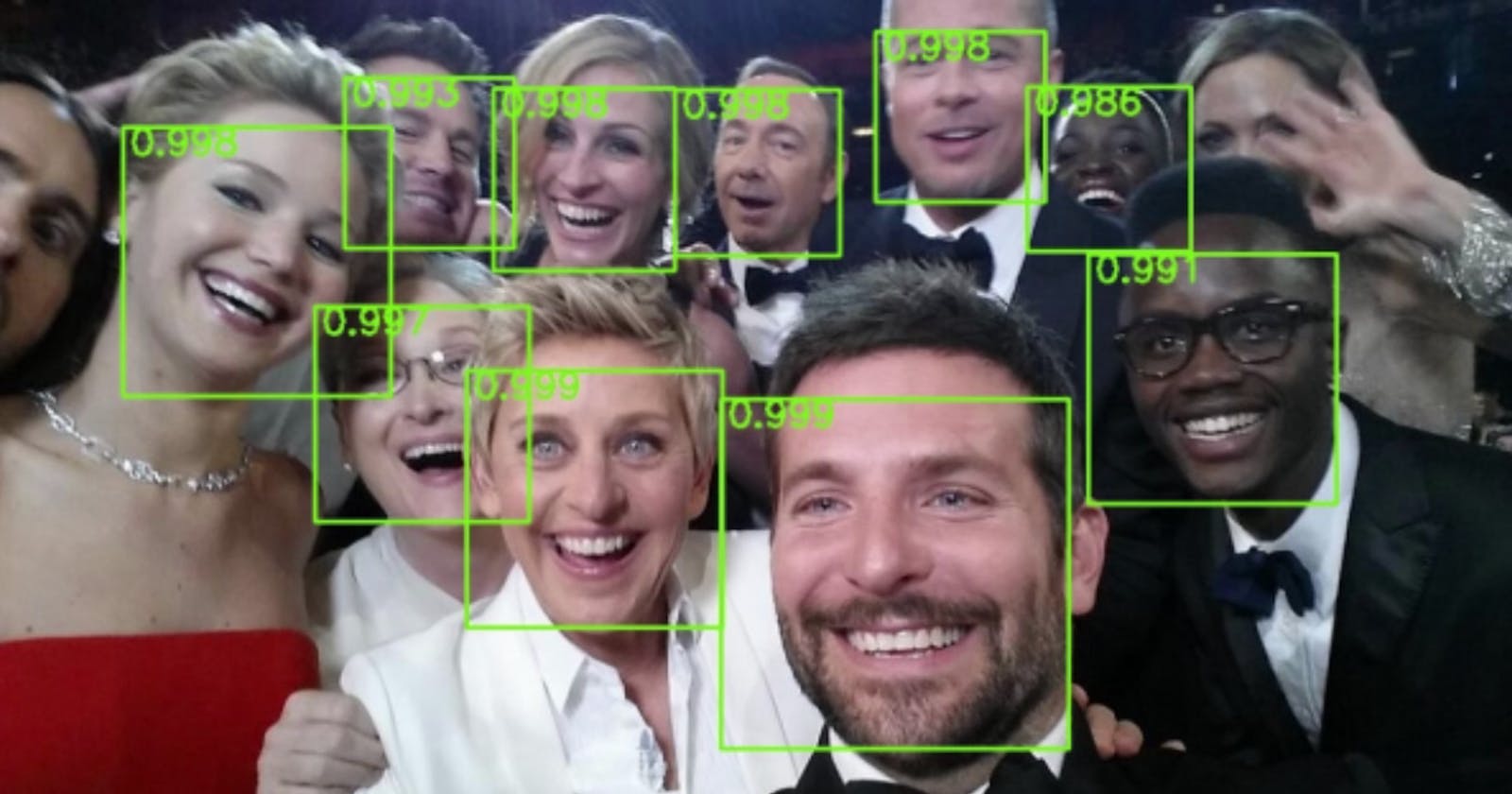
This should not be confused with facial recognition, which identifies who the face belongs to. Simply put, the goal of the computer in face detection is to draw a box around the face and give it a label. This task is illustrated below on the famous Oscars selfie:

Oscar selfie with faces detected, represented by green bounding boxes with confidences in upper-left hand corner [1].
This generalized task is widely known as object detection, a very popular concept in computer vision. Object detection is commonly used not only to detect faces, but objects of all kinds of categories, with different shapes and sizes. When an artificial neural network (model, computer, net, deep network, etc.) is trained on a dataset with examples of these images, it can learn to then locate and label the objects in new images with a certain confidence. If you're an expert on object detection, continue reading. If you're not, this is a good time to pause and read my blog post on single-shot-detection for faces here. This is one of the most robust ways to do face detection today, but it was not the first, or the most intuitive.
Let's backtrack a little:
The Viola Jones algorithm was an earlier method used to detect faces, and it is based on some intuitive concepts specific to faces. It does not use deep learning; instead, it uses Haar-like features and a cascade classifier to decide whether a given region contains a face. Haar-like features are predetermined, and some widely known and used features look like this:

Examples of Haar-like features [2].
I say it's more intuitive because we already know the features of a face, so it makes reasonable sense to "hard code" them. Dark regions around the nose, for example, would have a high correlation with the feature 2(b) inverted, and eyes might have a high correlation with feature 1(b).
And, similar to deep networks, it uses a sliding window approach and applies these features, one by one, to discover if there is a face in that window. The concept of checking for multiple features in decreasing order of importance is called cascading classifiers, and the logic looks something like this:

The structure of Viola-Jones cascade classifier [3].
where 1, 2, and 3, would be features, rejecting sub-windows would be a result of a poor match, and sub-windows that matched all features would be detected as a face. Once faces are detected, the regions can be passed on to other algorithms for identification, gender and age prediction, etc.
The order of important of the features to construct the cascade classifiers are learned through the AdaBoost method. That's what takes place during the "training" of the Viola-Jones algorithm, not to be confused with deep learning, which learns the actual features during training. Viola-Jones works well only on front-facing faces, and is actually used by Snapchat.
To summarize, deep learned methods and Viola-Jones are a couple of popular ways to detect faces, and these rely on features either learned through deep learning, or crafted using prior knowledge, such as skin tone, shape of face, and known facial features. Both of these have their pros and cons. From a training perspective, deep networks require less dependence on predetermined features and learn general, robust features, at the cost of requiring lots more data to learn from. In terms of practical applications, there would be no need to train a very deep network for something like Snapchat. However, on my research team, we need to detect faces at large scales, and if a face is far away, the Viola-Jones method wouldn't work.
This is where the similarities and differences start to become apparent between how computers handle this task and how human brains do. We know that feature detection is very important, but we don't know whether it involves a hierarchical coding like we've taught computers. This study published in Cell describes how a scientist curated a set of facial images with 50 distinct characteristics, or features, such as skin color and size of nose, and then showed the pictures to rhesus monkeys with an implanted electrode in their brain region responsible for recognizing faces. He found that each neuron from the implanted electrode responded in varying strengths to only one "feature". This means that neurons treat the face as a sum of parts, rather than one structure.
We theorize that there is one pathway for vision, and we handle object detection and face detection both, through this pathway. But we also know that faces are special. Faces are fundamentally different than any other kind of object that humans see. When babies finally open their eyes and begin to see, their neural responses to faces are much stronger than those for other objects, probably related to humans being social animals and the need to recognize family to survive. Although object detection is more closely related to the brain mechanism of vision than Viola-Jones is, it treats faces just like any other object, which is probably not similar to the brain's mechanism. This TED Talk by Dr. Nancy Kanwisher explains how one brain area is activated specifically when humans look at faces, in contrast to objects in general.
Also, humans don't mentally draw bounding boxes around the objects they see. For computers, it's easier to regress on four numbers that describe bounding box coordinates than it is to do segmentation, a pixel level training scheme that actually segments out the face from the background, as shown below. In this methodology, the goal is to segment the image into distinct parts that are meaningful and easier to analyze. This is a lot more computationally expensive than detection and a lot harder to get going in real time on devices.

Segmentation [4].
Deep networks and cascade classifiers are ingenious methods to perform tasks like face detection, and object detection in general. We know that some principles are similar to neuroscience, but we don't know quite yet enough about what our visual pathway is doing to be able to model it. To make it even more difficult to deduce what is actually going on in our own heads, the brain has a special knack for explaining away things that are actually happening (read about this phenomenon here). So our brains are it doing something like secretly drawing bounding boxes under the hood, we might not know about it even if we looked.
Sources
[1] “The Face Detection Algorithm Set to Revolutionize Image Search.” MIT Technology Review, MIT Technology Review, 18 Feb. 2015, technologyreview.com/s/535201/the-face-dete...
[2] Katalenic, Andelko & Draganjac, Ivica & Mutka, Alan & Bogdan, Stjepan. (2011). Fast Visual Tracking of Mobile Agents. 10.5772/14473
[3] Simultaneous analysis of driver behaviour and road condition for driver distraction detection - Scientific Figure on ResearchGate. Available from: researchgate.net/figure/The-structure-of-th.. [accessed 21 Mar, 2020]
[4] Multi-class semantic segmentation of faces - Scientific Figure on ResearchGate. Available from: researchgate.net/figure/Face-segmentation-a.. [accessed 21 Mar, 2020]
[5] Akash AA, Mollah AS, Akhand MAH(2016) Improvement of Haar Feature Based Face Detection in OpenCV Incorporating Human Skin Color Characteristic. J Comp Sci Appl Inform Technol. 1(1): 8. DOI: dx.doi.org/10.15226/2474-9257/1/1/00106