

Knowing English is important in today's world, but anyone who is born deaf cannot learn spoken languages the way we do. Deaf children cannot sound out words because they do not know what the letters sound like! Instead, they grow up learning American Sign Language (ASL) as their first language.

The letters ASL spelled out in American Sign Language.
ASL is a natural, signed language, which serves as the predominant language for Deaf communities in the United States and most parts of Canada. There is no universal ASL. Different countries have their own versions of the language. ASL is signed, meaning it is conveyed through hand movements and facial expressions rather than verbal tones. However, sign language is not so different from spoken languages.
ASL is natural and complete, meaning it still has the same linguistic properties as English, although the mechanics of the grammar are different. This makes it theoretically possible to translate between ASL and English, making it possible to teach deaf students English spelling, reading and writing.
Purdue University EPICS (Engineering Projects in Community Service) has partnered with the Indiana School for the Deaf to provide ways of helping their students learn better. My senior design team, Digital American Sign Language, is tasked with creating an intuitive tool to help the students learn English. Previous work on this project focused on creating a "dictionary" app which would allow students to click on English categories of words and then the words alphabetically sorted within the category, leading to the corresponding ASL sign. However, this design would require the students already know something unfamiliar before reaching what's familiar (English ->ASL) rather than the more intuitive way. What if we could come up with an ultra-efficient, intuitive way to teach the students English?
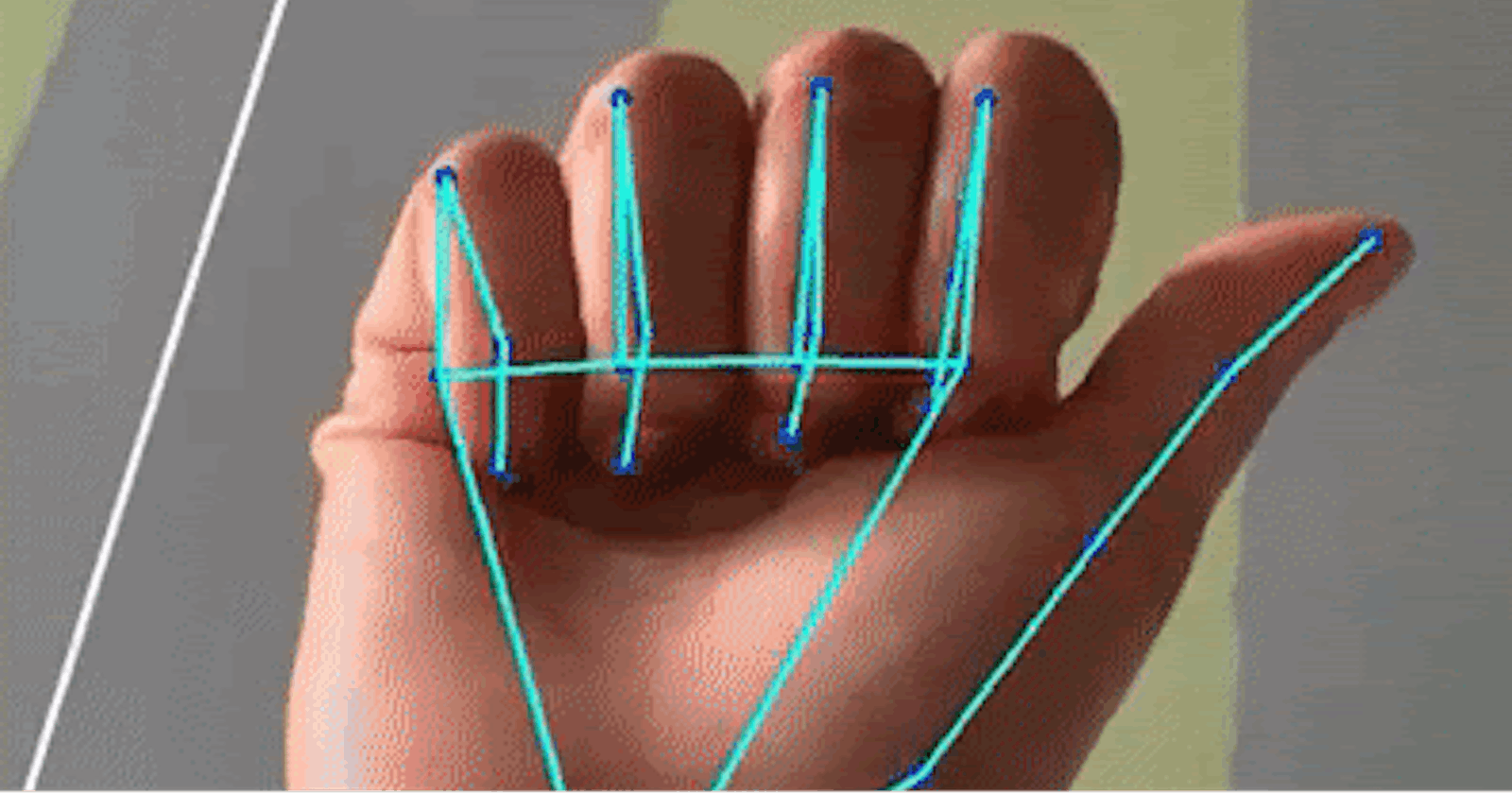
My team started brainstorming and came across this blog post that outlined a new method of on-device, real-time hand tracking developed by Google Research. While working on embedded vision on my research team, I learned about how difficult it is to do on-device computer vision. Since I had already worked with MobileNets and Single-Shot-Detection to do face detection on embedded devices, I understood how BlazePalm, an efficient version of these common computer vision methods, exploited the aspect ratios of palms (among other improvements), to turn SSD-MobileNet into an ultra-fast palm detector. The palm detector returns a bounding box around the hand in the image, which then serves as the input for the landmark model, which returns 21 landmark points on the hand. The two-stage pipeline, which consists of two neural networks, operates in real time, and on mobile devices. Of course, since this works on video, there is some element of tracking between frames, such as optical flow. The pipeline shown below operates on some, but not all frames of the input video:

How Google's real-time hand tracking pipeline works. First, a video frame is fed into the palm detector (BlazePalm), an object-detection method suited for palm detection. The result is a cropped bounding box around the hand in the image. This bounding box is fed into another model which predicts 21 landmark points, which are then overlayed with the hand in the bounding box, and finally stitched back into the image.
The result is some awesome real-time hand tracking:

Hand tracking working in real time. Credit: Google Mediapipe.
We realized two things after learning about Google's Hand tracking:
We could use the high-fidelity localization as a starting point to develop a real-time translator for ASL, thereby creating an intuitive (ASL -> English) and efficient (real-time) solution to teach students English spelling and phrases
The solution could run on iPads, which the students at Indiana School of the Deaf already own!
We got really excited and started learning how to the use MediaPipe framework and define the scope of our project.
ASL includes both static and dynamic signs to convey words, letters, and phrases. Some examples of static signs are the alphabet letters, A, S, L shown above. Dynamic signs, however, require movement to convey the letter, word or phrase. Letters J and Z are dynamic signs.
There are many other factors that determine the meaning of signs, like the speed of the sign, the location of the sign (above or below head in some cases), and facial expressions. We decided to limit our scope to working with hands, and break our project ino two categories: Finger spelling, to teach students how to spell the English alphabet, and everyday words and phrases, to help them translate commonly used phrases. Since our users at Indiana School of the Deaf are a younger audience, mostly in grades K-5, these would consist of simple words and phrases like household items and everyday activities.
Both categories would involve some element of static and dynamic signs. The alphabet would be static, save for two letters, so we started with that.
The first thing we did was train MobileNet v2 on this Kaggle dataset consisting of 87,000 images to see whether we could do real time classification just from the bounding boxes. It took only one epoch for model to train, since the images in each category are so similar to each other, and had a great validation accuracy of > 95%. However, this didn't work nearly as well in real time. All the images had a clean background, when in real time, there was a lot of noise, like my face right behind the hand. The model would see all the pixels, when it would have been better if the whole hand was segmented out or something.
Luckily, MediaPipe provides us with those 21 landmarks, normalized with respect to the bounding box. We started doing some research on what work had already utilized those points for another purpose, and came across this github repository that utilized 21 points to translate the signs into ASL letters A-Y, minus J. The group who developed this work had already done an architecture search, leading to a relatively simple feedforward neural network architecture, taking in 42 inputs (the x and y coordinates of each point in the set of 21 points), and delivering as output 24 class probabilities, one per letter. They also provided a pre-trained model on a small dataset of 6000 images, made available by running this updated Google Colab notebook. Their work describes another method of normalization on the inputs, a z-score normalization on the already normalized points with respect to the bounding box.
Converting this model to TFLite and integrating it into the iOS app using Mediapipe resulted in some pretty good results. However, since our team could not see where the image data came from to train the model, we wanted to train the model on our own data.
Based on the Official State Sign Language of Indiana, we took 1-minute videos of each letter of the alphabet and preprocessed these for landmarks, and used this data to train the model. Using this method, we were able to obtain about 30 times more data. Now, we were also sure that the ground truth of our model would be more tailored to Indiana's dialect. And real-time accuracy was quite high for the letters we signed ourselves. The result is shown below!
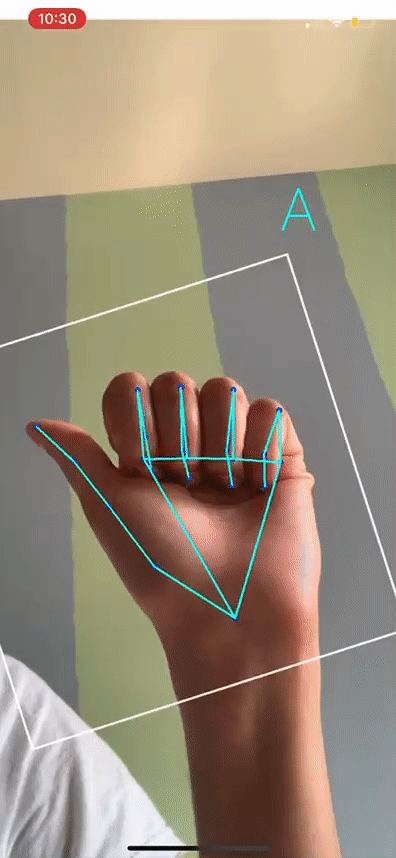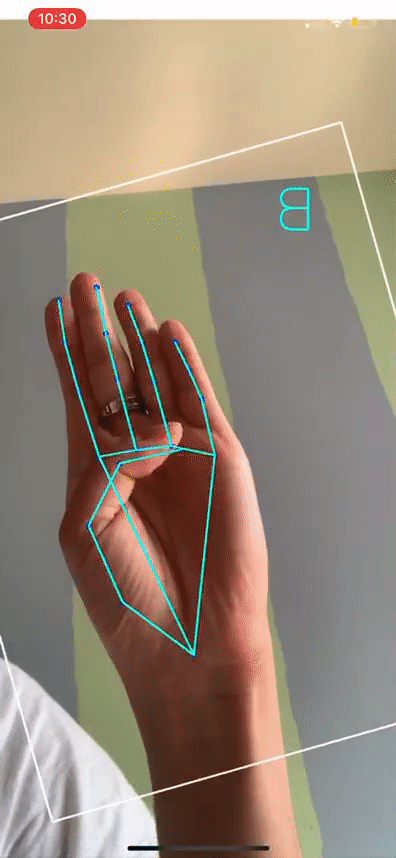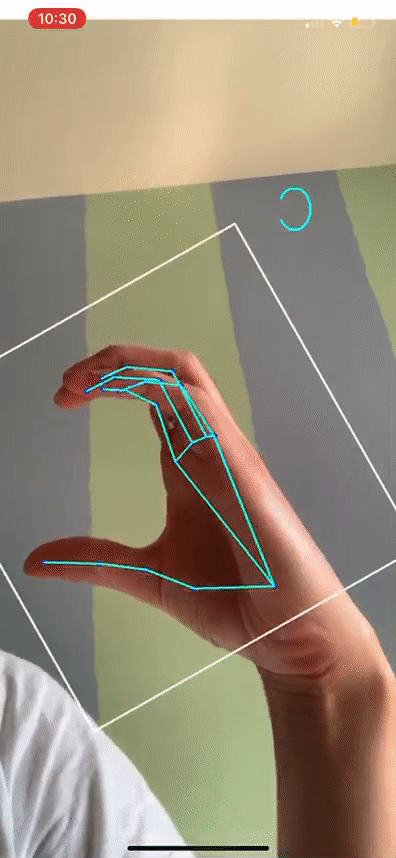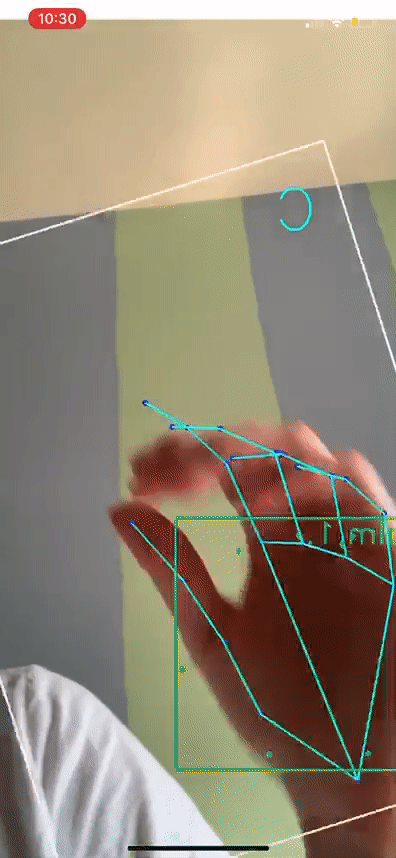
ASL alphabet translation working in real time on my hand. The letters are backwards due to the mirroring effect of the iOS Camera. We are still working out a way to keep it intuitive (mirrored) while flipping the displayed letters on mobile apps.
Once quarantine is over, we hope to meet with the Indiana School of the Deaf to do some user testing of our prototype.
An interesting thing to notice in the video is that towards the end, while detecting C, the landmarks and detected hand start to shift towards my fingers at the top of the bounding box. This is likely a side effect of the tracking component of MediaPipe that allows fast real-time hand tracking, such as optical flow. MediaPipe likely uses optical flow or a similar tracking method between frames to refrain from performing detection on every single frame, which would be slow. Detection is usually performed every n frames, with tracking methods to "fill in the gaps" between detections. The reason the "in between" frames are not so exact is because those resulting bounding boxes and landmark points are only based on previous frames and pixel movements. The exact bounding boxes would then be detected at the next detection frame (where BlazePalm is actually run again). So where the detection starts to go wrong, BlazePalm is not actually being run. Since our work is based on MediaPipe's output, we cannot fix this behavior ourselves without changing the tracking method or frequency of detection that MediaPipe is using. This may be necessary as we continue out work since our app will be used in an academic context to teach students, and we value accuracy over speed.
Our next goal is to do real-time video translation of words and phrases that are dynamic. This will likely be done using 3D CNNs and RNNs or LSTMs to deal with the temporal challenge of dynamic signs. Stay tuned!